Have you heard about JSTOR’s Text Analyzer tool? The Text Analyzer tool accepts PDFs, Microsoft Word documents, or images of text and generates a list of research articles and subject terms to help you find new research sources. Watch this video to learn more about JSTOR’s Text Analyzer tool.
You need to include the YouTube video id in the id attribute! example: url="https://www.youtube.com/watch?v=Cl6pLzvxD8E"
How to try the Text Analyzer tool for the first time.
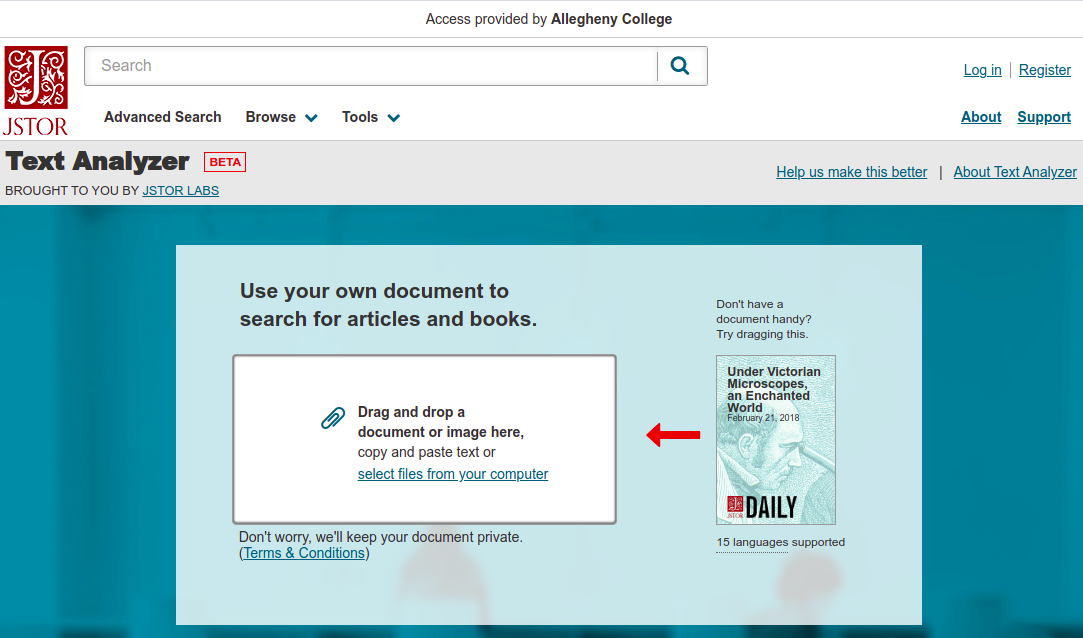
- Go to JSTOR Text Analyzer to get started.
- Upload a document with text in it. It can be an article you found, a paper you’re writing, or a picture of a page from a book. If you want experiment, JSTOR provides a test document you can click and drag to upload into the tool. The Text Analyzer tool will process the document and redirect you to the results page.
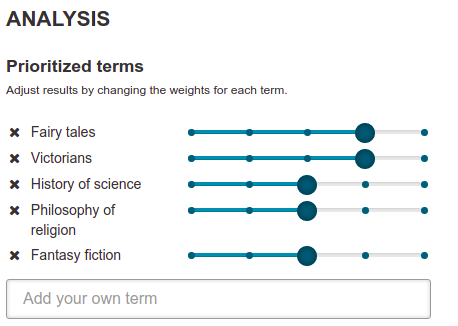
- On the results page, you can adjust which prioritized terms are used and how important they are in the Analysis section. These terms are autogenerated, but you can also add your own if the tool did not include the ones you want.
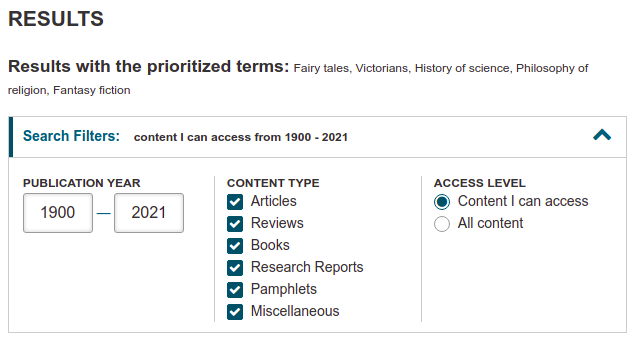
- You can also adjust important search filters like the publication year, content type, and access type in the Search Filters dropdown menu.
- Finally, you can browse through the list of results generated by the tool.
File types supported
You can upload or point to many kinds of text documents, including: csv, doc, docx, gif, htm, html, jpg, jpeg, json, pdf, png, pptx, rtf, tif (tiff), txt, xlsx. If the file type you’re using isn’t in this list, just cut and paste any amount of text into the search form to analyze it.
Languages supported
English, Arabic, (simplified) Chinese, Dutch, French, German, Hebrew, Italian, Japanese, Korean, Polish, Portuguese, Russian, Spanish and Turkish (see FAQ, below, for details)